
…and it is your customer data.
Nine out of ten purchases still take place in the store. That means that with each swipe of the credit card, customers send a strong signal of preference by means purchase. But today this signal is lost into one of these: DMP, CRM, or another three-letter acronym for your data sinks.
So why not take make use of this rich data?
Point-Of-Sale (POS) data can provide insights into the real-time shopping trends in a local area or what items/brands an individual shopper prefers and/or has already purchased. It’s only logical that with a bit of wizardry with this data, you should be able build better models that represent your shopper base and provide more relevant personalization for shoppers regardless of the channel they are utilizing. POS data is proving already to help supercharge online personalization for web, mobile and email as some of our more innovative retailing partners are finding.
We have worked with a few adventurous retailers ($10B+ office supplies retailer and $1B+ upscale department store), to quickly test this hypothesis on these next generation recommendation models. We integrated in-store transactions into the Relevance Cloud™ and ran a test. One that used offline+online purchase data to build recommendation models and a control version that used just the online purchase data.
After 45 days, we found that strategies that used offline+online data drove +1% incremental lift in revenue per session sitewide (beyond the performance of existing recommendations). One percent lift may not seem much at first glance, but this is a significant return for billion-dollar retailers with little effort. And there is even more room for improvement. The retailers included in this test did not have a perfect offline-to-online product catalog overlap, meaning there is still incremental value that can be derived once these SKUs are resolved.
In the process we also discovered some key insights about the omnichannel shopper’s behavior:

Never leave another customer data set at the till again
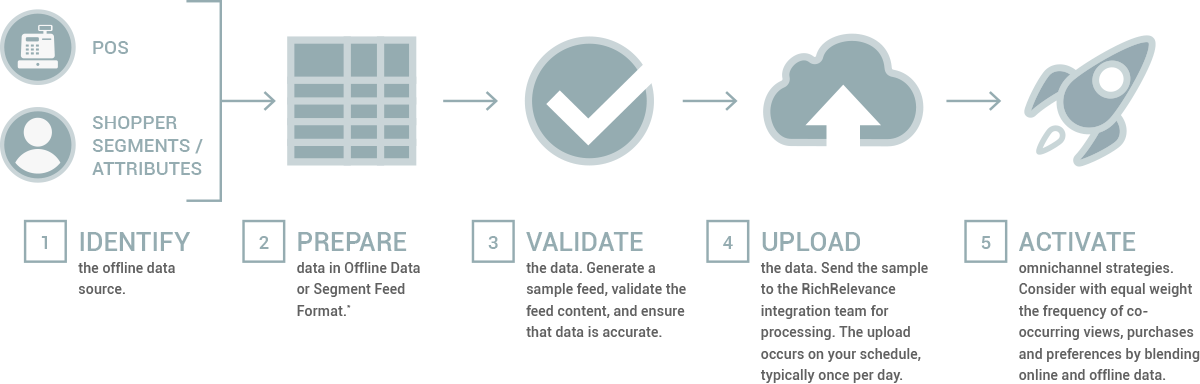
Offline data ingestion is a simple process. RichRelevance Omnichannel strategies take the following datatypes and offer personalization based on a 360-degree view of individual consumers:
POS Transactions: Purchases, orders and returns that contains a purchase date, item(s), customer ID, and monetary value.
Shopper Segments and Attributes: Customer or household segments such as gender, location, loyalty tier, etc. from homegrown databases, CRM records or third-party resources (Merkle, Acxiom, LiveRamp, BlueKai, etc.).
So when emptying your cash register at the end of the day…
…don’t leave your customer data behind. Put it to work to get more out of your online personalization and build richer experiences.
Learn more about Offline Data Ingestion.
The Big Data revolution at Google, Facebook, Amazon and Apple has transformed the consumer journey across channels, and even helped turn a presidential election. This transition simultaneously poses tremendous challenge and opportunity to retailers.
In our session “How Relevance Can Get Your Brand Elected” at last week’s NRF Big Show, Rayid Ghani (Obama for America’s Chief Scientist) and I shared how data scientists have utilized key methodologies for capturing value and turning Big Data to smart data—using it to win votes and create profit. The analogies between data usage in the Obama campaign and my experience at Amazon and RichRelevance are deep: there are three ways to use data in operations, and it is necessary to take small steps toward a very specific goal using an agile, fail-fast methodology.
The methodologies for data usage are analytics; prediction and interruption; and optimization. They transcend the emergence of “Big Data” and extend in their impact from the last century, as do the learnings from their failures. The “big transformative project” is doomed to fail; only iterative implementations see the huge ROI of data-oriented technologies.
As I traveled the exhibit hall, I reached my personal predictions for 2014:
- 2014 will test us: We must know our identity—who are we to our customers and how we maximize that. This challenge exists in a highly competitive and unfriendly ecosystem: Amazon is on a tear and will not stop; will Google, eBay, Apple and Facebook turn out to be friend or foe?
- Omni-channel ROI at scale: 2014 will be the first year with enough historical case studies of successful omni-channel strategies to support systemic investment. Retailers can invest in 5-10 major initiatives and each can build on the successes/failures of past years.
- Emergence of Big Data, Year 2 of 5: Big Data is a long-term trend. We are still in the early adopter phase, where practitioners familiar with the technology and business can be successful, but not enough business people fully understand the technology’s capabilities, ROI or risk in order for 2014 to be the year of mass scale. That said, Big Data is complex and will require numerous years of investment and learning to reach maturity. Executives know that, so this year will see significant investment from both capital and time budgets.
I invite you to learn more about how you can turn your Big Data into smart data for a relevant brand experience by visiting https://richrelevance.com/nrf/.
In this volume, we conclude with Privacy and Security.
Privacy and Security
For our final examples I want to dig into the notions of privacy and security in big data settings. These are and always will be critical concerns.
We begin with financial information and e-commerce. In the early days of Amazon, there were a significant number of customers who were very concerned about the security implications of entering their credit card numbers online. The specific concerns varied, but they almost always involved the possibility of a gang of nefarious hackers gaining access to credit card numbers and using them to make fraudulent purchases.
By Doug Bryan, Data Scientist, RichRelevance.
 The oldest and largest marketing data aggregator, Acxiom, recently opened up its database to let individuals see and edit the data that the company has collected about them. Data scientists and marketers have been viewing the data and, often, chuckling at its inaccuracy. Acxiom admits that up to 30% of its data is wrong, and yet it’s the industry leader. How can Acxiom make so much money with data that’s only 70% accuracy? Simple: Most marketers’ data is worse, and in the land of the blind the one-eyed man is king.
The oldest and largest marketing data aggregator, Acxiom, recently opened up its database to let individuals see and edit the data that the company has collected about them. Data scientists and marketers have been viewing the data and, often, chuckling at its inaccuracy. Acxiom admits that up to 30% of its data is wrong, and yet it’s the industry leader. How can Acxiom make so much money with data that’s only 70% accuracy? Simple: Most marketers’ data is worse, and in the land of the blind the one-eyed man is king.
In this volume, we discuss Data Mining and The Birthday Paradox.
Data Mining and The Birthday Paradox
We’ve all heard of the Birthday Paradox. Put 23 randomly chosen people in a room and there is a 50% chance that two or more have the same birthday. Put 57 people in the room, and the chance is 99%. Do those people have anything more in common because they were born on the same day of the year? Astrologers will say yes, but most scientists would say there is no evidence to support that claim.
What does this have to do with big data? The answer is that generalizations of the math behind the birthday paradox tell us that we will—not just that we can but that with near 100% certainty we will—draw meaningless conclusions if we just look at enough variables. In fact, we can show that if we generate a large number of streams of completely random data, some of them will look like others.
The problem is, we can easily forget this when we look at big data sets with lots and lots of variables. These are the kind of things we see in what is called data exhaust. Data exhaust is the vast stream of data gathered and logged by digital devices ranging from mobile phones to engine sensors in cars to video cameras in public spaces to instruments on particle accelerators.
Look at a lot of this data, and you will find spurious correlations. This is what Principle 3 is all about. Statisticians have known about Principle 3 for decades, and have techniques for trying to deal with it. The best technique, however, is and always has been a controlled scientific experiment, as Principle 2 advocates.
In this volume, we discuss Product Recommendations.
Product Recommendations
Product recommendations span far more than just films. We have all seen these recommendations hundreds of times while shopping online. You are looking at one product, and five or ten others are recommended, either as alternatives to consider, or perhaps accessories, based on what shoppers who are in some way like you have done in the past.
Many frame the product recommendation problem as one of prediction. How can I predict which product you are likely to buy next, and recommend it to you? That’s actually a lot better than what contestants were asked to predict for the Netflix Prize. Unfortunately, prediction is not really the problem at all. If I am 100% accurate in my prediction, and you buy exactly what I predicted you would, I haven’t changed anything. I haven’t generated any incremental value for the retailer, or created much immediate value for the shopper, other than perhaps saving them a bit of time.