RichRelevance Inc. faces one of the prototypical big data challenges: lots of data, and not a lot of time to analyze it. For example, the marketing analytics services provider runs an online recommendation engine for Target, Sears, Neiman Marcus, Kohl’s and other retailers. Its predictive models, running on a Hadoop cluster, must be able to deliver product recommendations to shoppers in 40 to 60 milliseconds — not a simple task for a company that has two petabytes of customer and product data in its systems, a total that grows as retailers update and expand their online product catalogs.
Today, I’m super excited to announce the launch of the Relevance Cloud™– what we at RichRelevance believe to be the most comprehensive personalization solution for retail today. The Relevance Cloud is a re-imagining of all RichRelevance products with new features and more simple ways to access, use and implement each of RichRelevance’s products.
Our Discover, Engage, Recommend and Build products empower retailers to deliver and innovate brand-centric customer experiences that span the customer lifecycle across all channels. Each of these products is powered by the Personalization Graph—a unified customer view which aggregates key data on customer behavior, content, context and products. The Personalization Graph is the next generation customer view. Powered by Big Data technologies, it’s flexible, streaming and scalable. Unlike the rigid CRM-centric view of the customer, the Personalization Graph sees each consumer as a fluid, ever-changing and increasingly complex stream of events and touchpoints, reflecting the reality of today’s consumers.
Here are the parts of the Relevance Cloud:
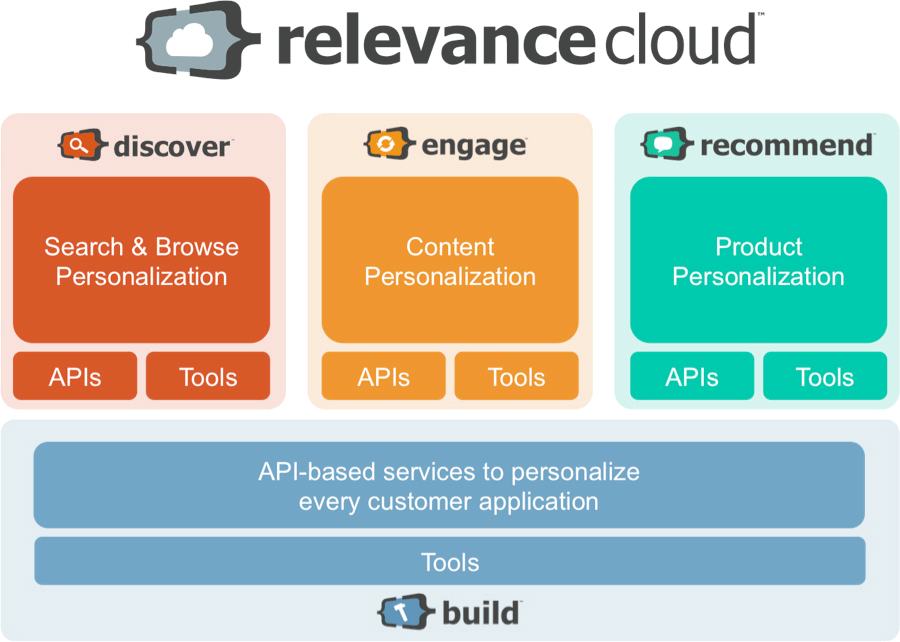
Especially exciting to me is the debut of our Build API-based services (I am an engineer after all! ☺). The opening up of our SOA and platform are key to unlocking the next revolution in personalization. Personalization is not simply an application (e.g., the market-leading Recommend product recommendations) but a capability which must be deeply integrated into the fabric of every customer-facing moment, incorporating the essence of each retailer’s unique customer strategy. Data science as a skill set continues to mature within retailers, and with Build, we provide an open, flexible architecture for our retailers’ data science teams to create entirely new customer experiences.
Case in point: one of our long-time customers, Wine.com employed a “bring your own algorithm” approach to test and deploy a “similar products” recommendation strategy, incorporating their unique knowledge of their specific assortment. It ended up driving $5 per click—becoming one of their best strategies in terms of revenue per click and increasing overall orders and revenue, not to mention dazzling their customers by putting forward their industry specific expertise.
RichRelevance’s Relevance Cloud manages all the heavy lifting (fault-tolerant infrastructure, the operationalization of data, etc.) so that our customers can focus on what they do best: designing differentiated experiences that speak to shoppers 1:1, ensuring that personalization delivers a significant market advantage. I hope you are excited as I am about this next generation of personalization!
Personalization is what empowers retailers to create a 1-1 relationship with customers online. By tracking engagement and other KPIs, you can quickly take stock of how are you doing with those relationships.
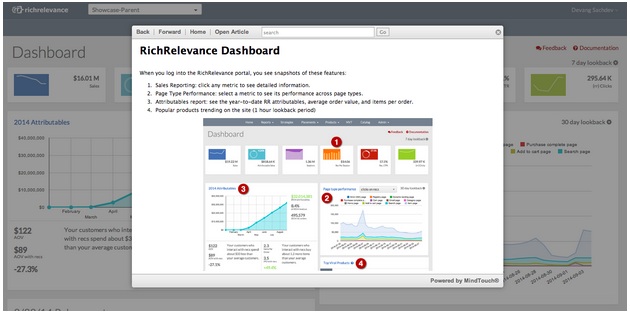
The new RichRelevance dashboard is the perfect tool for putting richer reports with more data at your fingertips, so that you’re always in tune with your site personalization. The new dashboard pulls back the curtain to showcase your data in a more digestible, visually appealing way. When your reports are eye-friendly, organized and automated, you can assess the status and impact of your site personalization within minutes.
Here are three quick ways to dive into the dashboard.
1. Check and share the vitals
Our brand new Lookback Summary is a detailed tile band that displays an at-a-glance summary of your sales and recommendation metrics. You can configure the lookback period to be a day, week, month or any number of days up to 90. You can also click any tile to access an expanded view of the graph. Take a screenshot and share metrics with key stakeholders in just a few clicks!

2. Track the value add
The Attributables Report tile is another new addition to help you track the impact of RichRelevance recommendations on your site–specifically through change in average order value (AOV) and items per order (IPO).
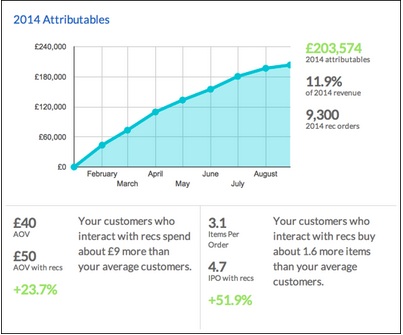
3. Access more detailed data and then some
Other significant enhancements include the Page Type Performance tile, where you can view the performance of different metrics for various pages on your site, and the Viral Products tile, which displays the most viewed products and takes you to detailed Merchandising Reporting. Best of all, feature documentation can be accessed within the feature page itself.
Try today
The new RichRelevance dashboard is designed to upgrade your experience and provide site health visualization, easy controls and usability improvements throughout. If you haven’t done so already, we encourage you to log in to your dashboard and play around. We believe that in order to provide you with more of the tools that you love, we need to work together. So, tell us what you’d like to see in the next set of improvements using the comments section below.
Malcolm Gladwell a récemment vulgarisé le terme « outlier » (valeur aberrante) en l’utilisant pour désigner des personnes performantes. Toutefois, dans le contexte des données, les valeurs aberrantes sont des points de données très éloignés d’autres points de données, c’est-à-dire atypiques… Read more
Malcolm Gladwell recently popularized the term ‘outlier’ when referring to successful individuals. In data terms, however, outliers are data points that are far removed from other data points, or flukes. Though they will make up a small portion of your total data population, ignoring their presence can jeopardize the validity of your findings. So, what exactly are outliers, how do you define them, and why are they important?
A common A/B test we like to perform here at RichRelevance is comparing a client’s site without our recommendations against with our recommendations to determine the value. A handful of observations (or even a single observation) in this type of experiment can skew the outcome of the entire test. For example, if the recommendation side of an A/B test has historically been winning by $500/day on average, an additional $500 order on the No Recommendation side will single-handedly nullify the apparent lift of the recommendations for that day.
This $500 purchase is considered an outlier. Outliers are defined as data points that strongly deviate from the rest of the observations in an experiment – the threshold for “strongly deviating” can be open to interpretation, but is typically three standard deviations away from the mean, which (for normally distributed data) are the highest/lowest 0.3% of observations.
Variation is to be expected in any experiment, but outliers deviate so far from expectations, and happen so infrequently, that they are not considered indicative of the behavior of the population. For this reason, we built our A/B/MVT reports to automatically remove outliers, using the three standard deviations from the mean method, before calculating results, mitigating possible client panic or anger caused by skewed test results from outliers.
At first glance, it may seem odd to proactively remove the most extreme 0.3% of observations in a test. Our product is designed to upsell, cross-sell, and generally increase basket size as much as possible. So, in an A/B test like the above, if recommendations drive an order from $100 to $200, that’s great news for the recommendations side of the test – but if the recommendations are so effective that they drive an order from $100 to $1,000, that’s bad news because a $100 order has become an outlier and now gets thrown out.
In order for a test to be statistically valid, all rules of the testing game should be determined before the test begins. Otherwise, we potentially expose ourselves to a whirlpool of subjectivity mid-test. Should a $500 order only count if it was directly driven by attributable recommendations? Should all $500+ orders count if there are an equal number on both sides? What if a side is still losing after including its $500+ orders? Can they be included then?
By defining outlier thresholds prior to the test (for RichRelevance tests, three standard deviations from the mean) and establishing a methodology that removes them, both the random noise and subjectivity of A/B test interpretation is significantly reduced. This is key to minimizing headaches while managing A/B tests.
Of course, understanding outliers is useful outside of A/B tests as well. If a commute typically takes 45 minutes, a 60-minute commute (i.e. a 15-minute-late employee) can be chalked up to variance. However, a three-hour commute would certainly be an outlier. While we’re not suggesting that you use hypothesis testing as grounds to discipline late employees, differentiating between statistical noise and behavior not representative of the population can aid in understanding when things are business as usual or when conditions have changed.
It’s no secret that many households spend on the latest and greatest TVs when leading up to the Super Bowl. In fact, after I initially began working in retail a number of years back, I was surprised to find out that not only do people buy TVs specifically for Super Bowl parties, but some also go through the trouble of returning the TVs after their party (I know, exhausting)! Regardless of the enormity of your Super Bowl party, team affiliation (go 49ers!) and how many wings you’ll devour, there’s always some fun data to be explored.
Through studying normalized data across our retail base (over 100+ sites in the U.S.), we found some interesting trends on TV purchases leading up to the big game. In the image below, you’ll see that there are some states that prefer to spend more on TVs than others. The darker green states spend more than the lighter green states. The average selling price of TVs ranged from $300 – $1,100, with Wyoming at the high end of that spectrum (mean price $1,119), and Rhode Island on the low end (mean price of $366). Wyoming winters are cold, so I don’t blame them!
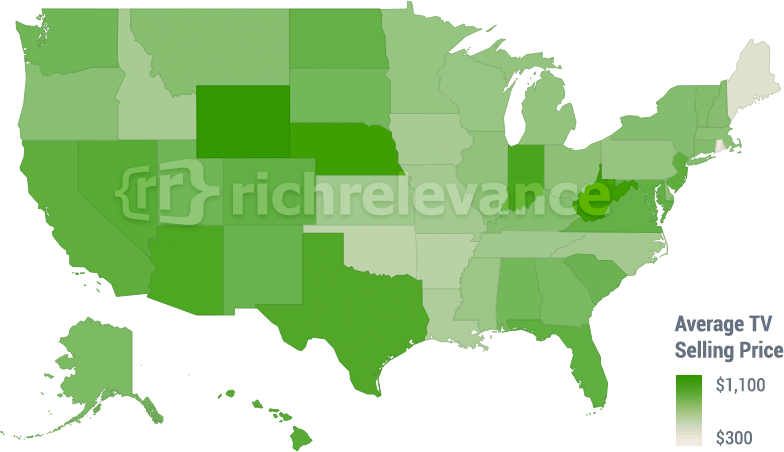
It should come as no surprise that the most-searched TV brands were Samsung, Sony and Vizio. However, the most purchased brands were Vizio, Westinghouse, Magnavox and Element. It seems our consumers are still pretty cost-conscious, but are still buying for the big game, which leads to our next point below.
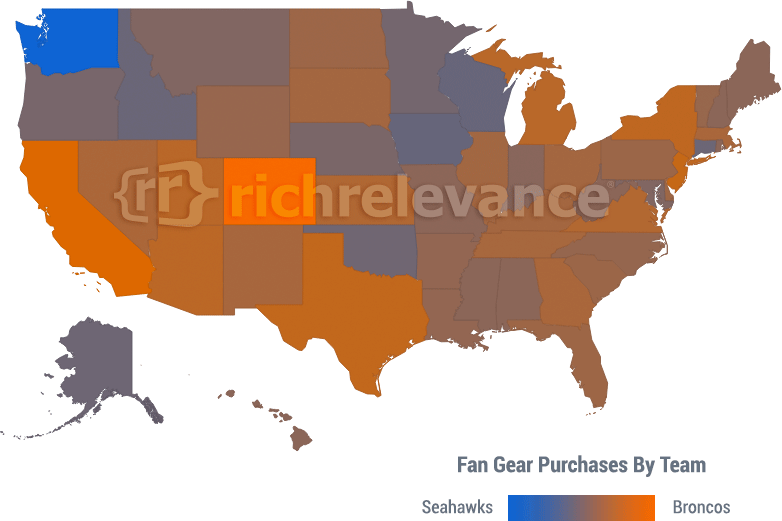
What do purchasing habits of Super Bowl team gear tell us about who consumers would like to win? We indexed team gear purchases by geo-location below (orange is Denver Broncos and blue is Seattle Seahawks). I’ll let the graph speak for itself, but I’m pretty sure fans are confident Peyton plans to throw some more “duck TDs” this weekend.